|
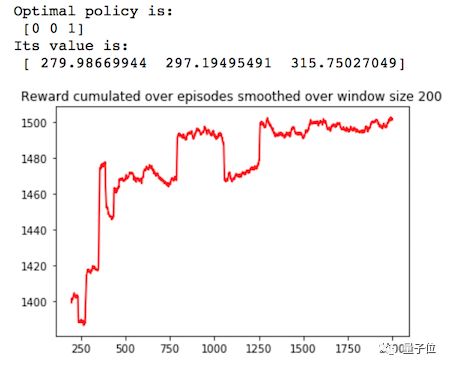
这种界限方法是目前最常用的,基于这种界限后面也有许多改进工作,包括UCB-V,UCB*,KL-UCB,Bayes-UCB和BESA[4]等。 下面给出经典UCB算法的Python实现,及其在Q-Learning上的应用效果。
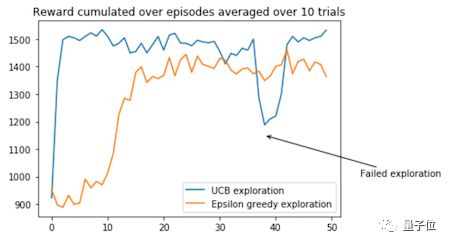
UCB搜索算法应该能很快地获得高额奖励,但是前期搜索对训练过程的影响较大,有希望用来解决更复杂的多臂******机问题,因为这种方法能帮助智能体跳出局部最优值。
Q-Learning是强化学习中最常用的算法之一。在这篇文章中,我们讨论了搜索策略的重要性和如何用UCB搜索策略来替代经典的ε-greedy搜索算法。 更多更细致的优先策略可以被用到Q-Learning算法中,以平衡好利用和探索的关系。 |
热门关键词: