|
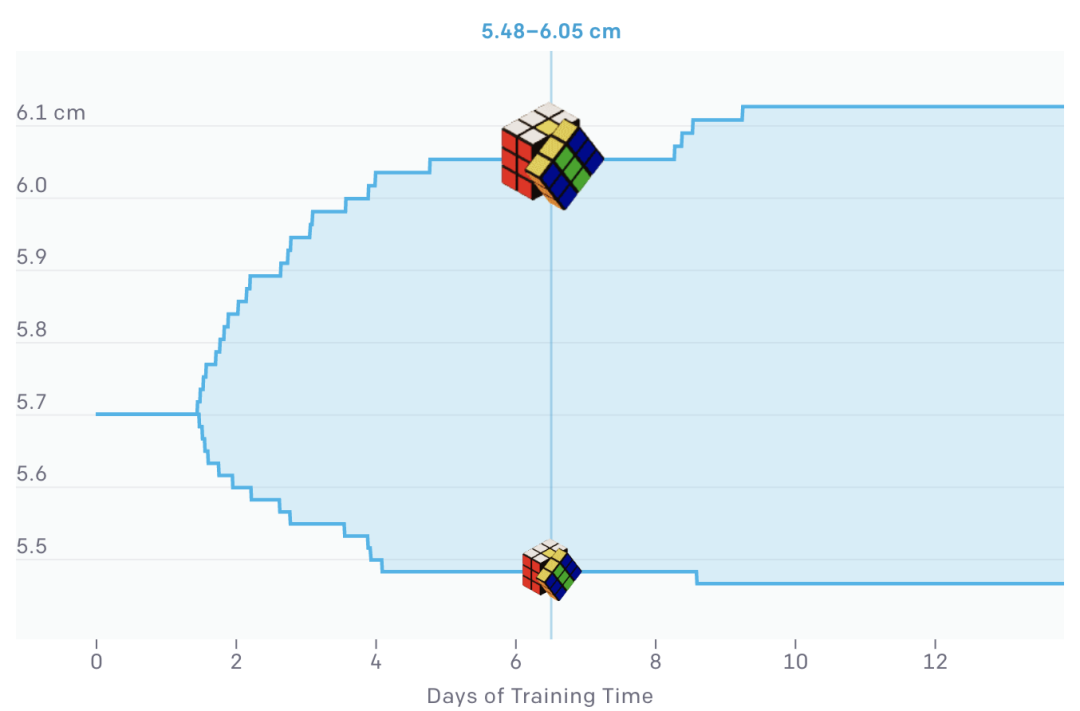
随机化的参数之一是魔方的大小(上图)。ADR从一个固定大小的魔方开始,随着训练的进行,逐渐增加随机化的范围。我们将同样的技术应用于所有其他参数,如魔方的重量、机器人手指的摩擦力和手的视觉表面材料等。因此,神经网络必须学会在所有这些越来越困难的条件下解魔方。
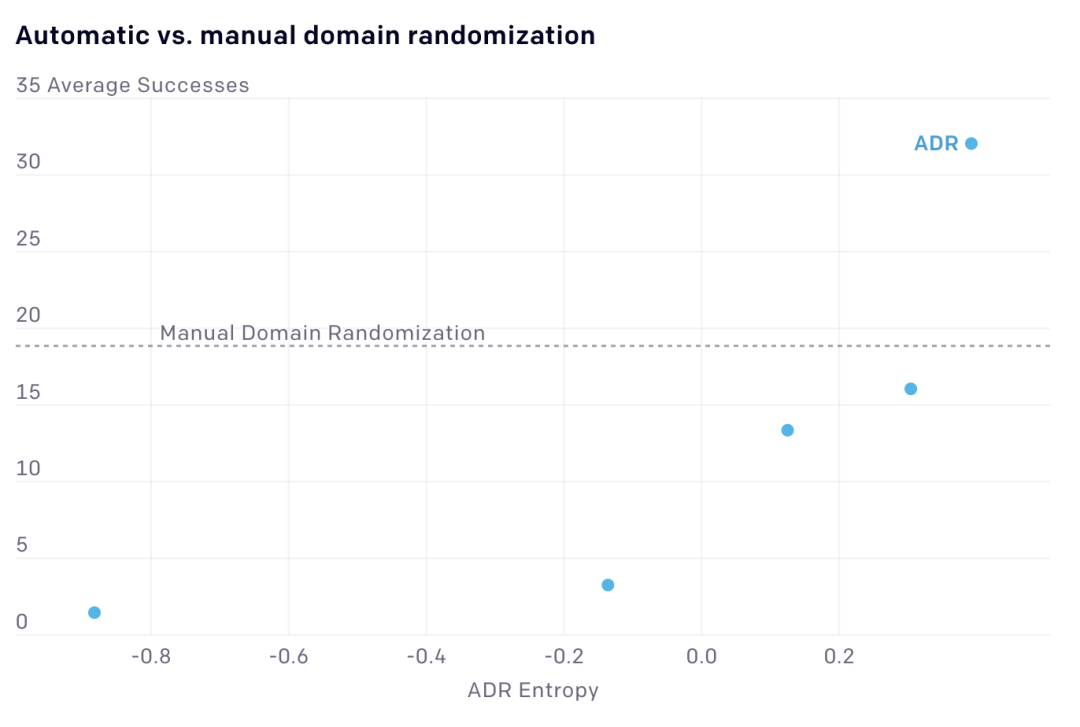
Domain randomization要求我们手动指定随机化范围,这很困难,因为太多的随机化会使学习变得困难,但太少的随机化则会阻碍迁移到真正的机器人。ADR通过自动扩展随时间变化的随机范围来解决这个问题,不需要人工干预。ADR消除了对领域知识的需求,使我们的方法更容易应用于新任务。与手动域随机化相比,ADR还使任务始终具有挑战性,训练从不收敛。 在魔方块翻转任务中,我们将ADR与手动域随机化进行了比较,这个任务已经有了一个强大的基线。在开始阶段,ADR在真实机器人上的成功次数较少。但随着ADR增大熵值(熵值是环境复杂性的度量),性能最终会比基线性能翻倍,无需人工调整。 利用ADR,我们能够在仿真环境中训练神经网络,再用到真实机器手上解魔方。这是因为ADR将网络暴露于无穷无尽的随机模拟中。正是由于训练过程中的这种复杂性,使网络可以从模拟世界转移到现实世界,因为它必须学会快速识别和适应它所面对的任何物理世界。
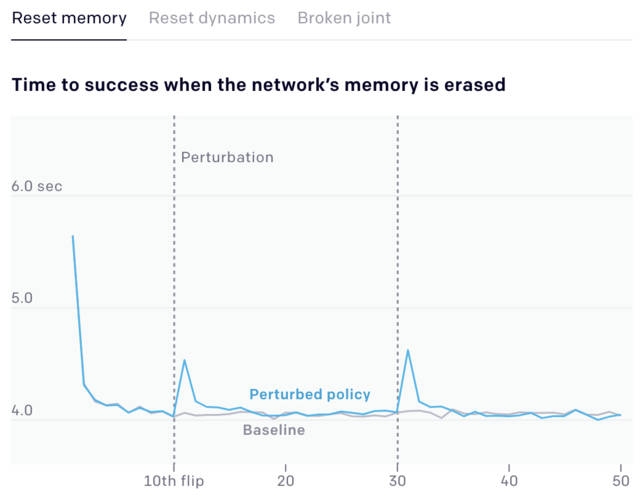
为了测试我们的方法的局限性,我们在单手解魔方的时候做了各种各样的干扰实验。这不仅测试了我们控制网络的稳健性,也测试了我们的视觉网络,在这里我们用视觉网络来估算魔方的位置和方向。 我们发现,我们用ADR训练的系统对干扰的稳健性令人惊讶,尽管我们没有对这些干扰条件进行过训练:在所有干扰测试中,机器手都能成功地完成大多数翻转和旋转面,尽管性能没有达到最佳。 我们认为,元学习,或learning to learn,是构建通用系统的一个重要前提,因为元学习使它们能够快速适应环境中不断变化的条件。ADR背后的假设是,一个记忆增强网络与一个充分随机化的环境相结合,导致了emergent meta-learning,其中网络实现了一个学习算法,允许自己快速调整其行为以适应其所部署的环境。 为了系统地测试这一点,我们测量了神经网络在不同的扰动下(如重新设置网络的内存、重新设置动态、或断开一个关节)每次翻转魔方(旋转魔方使不同颜色的面朝上)成功的时间。我们在仿真环境进行这些实验,这使我们能够在一个受控的环境中进行超过10000次的性能测试。
一开始,随着神经网络成功地完成更多的翻转,每次连续成功的时间都在减少,因为神经网络学会了适应。当施加干扰时(上图中垂直的灰色线条),我们看到了成功时间的一个峰值。这是因为网络采用的策略在变化的环境中不起作用。然后,网络重新学习新的环境,我们再次看到成功的时间减少到先前的基线。
我们使用可解释性工具箱中的一个构件,即非负矩阵分解,将这个高维向量压缩成6组,并为每组分配一个独特的颜色。然后在每一步中显示当前主导组的颜色。 实际上会玩魔方的机器人并不只有Dactyl一个。那些专门被设计用来解魔方的机器人,甚至可以比Dactyl更快地处理三阶、甚至更高阶的魔方,那么为什么只有Dactyl获得如此高的评价呢? |
热门关键词: